Tutorial - Workflow in FHIR
- Tutorial code on GitHub hapi-py-fhir-tutorials -- workflowOperator.py.
Background
Scenario
Recently, our researcher Jiali launch a study. This study is about convert a SDS format dataset into a FHIR format, and she also need to create a workflow and run the workflow for each individules. What's more, she also need to manange the workflow results for each patient. Then, she also provides some basic information for us:
SDS dataset:
 Here you can find out under SDS dataset primary folder, there are two patient subjects, after we deal with the dataset, we can get the above information: 1. Patients' name: Aniyah, and Linman Zhang. 2. Their EHR data - age and body temperature. 3. The identifiers for both of them. So, which FHIR resources that we can choose for storing these EHR data? Obviously, the Patient and Observation are our first choice.
Here you can find out under SDS dataset primary folder, there are two patient subjects, after we deal with the dataset, we can get the above information: 1. Patients' name: Aniyah, and Linman Zhang. 2. Their EHR data - age and body temperature. 3. The identifiers for both of them. So, which FHIR resources that we can choose for storing these EHR data? Obviously, the Patient and Observation are our first choice.Workflow discription:

Obviously, the workflow description has aleady given a very detailed information: identifier, target, and actions. So we can choose PlanDefinition resource to store these informations.
- Researcher detail:

As for the researchers, their information we can store in the FHIR Practitioner resource.
With these nice information above, we can draw a FHIR resources relationship/structure dragram for how can we organize the data in FHIR server.
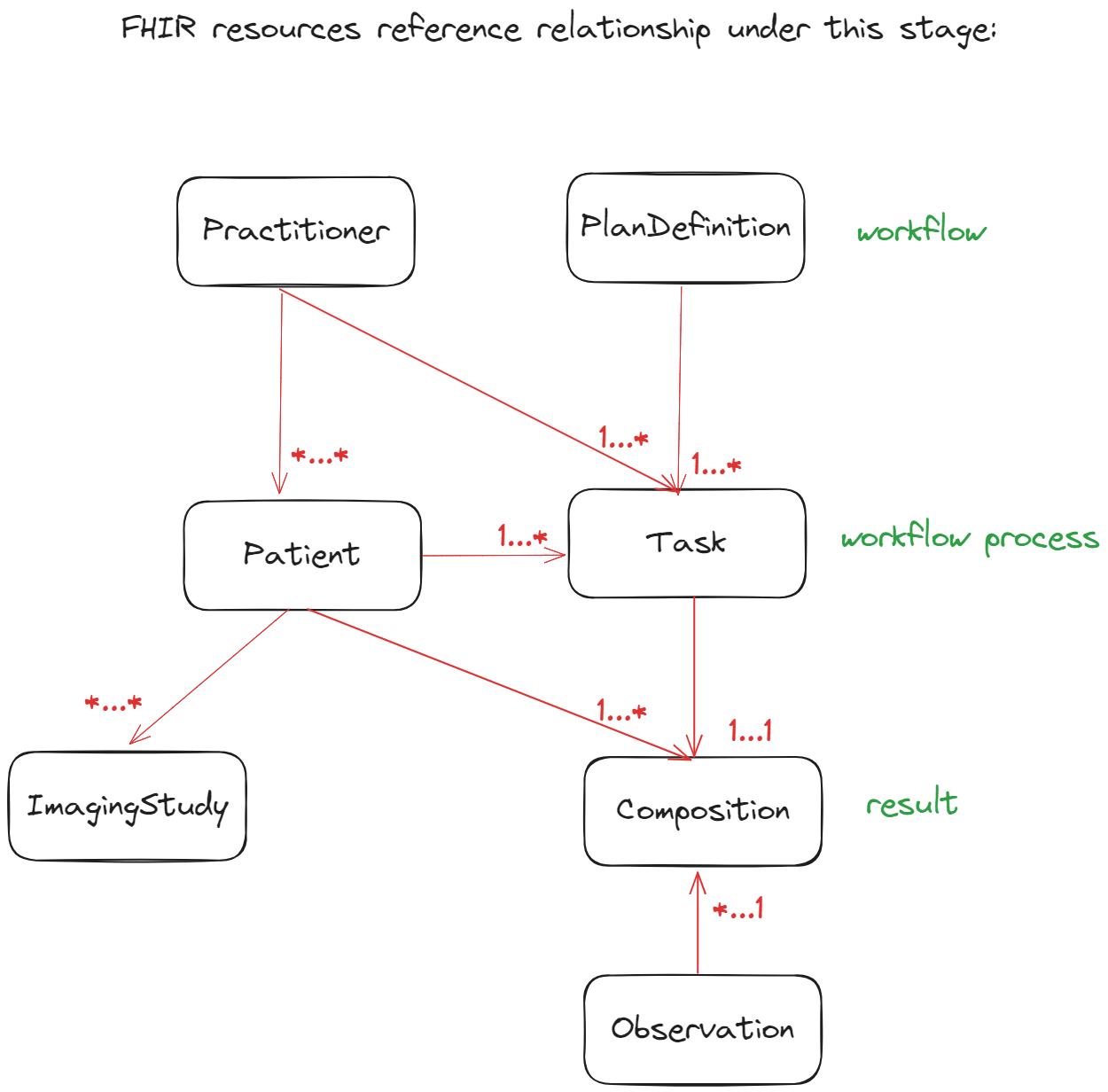
The basic ideas for this relationship diagram are:
- The Practitioner (researcher) and PlanDefinition (workflow) are independent.
- All Patient resources are managed by Practioner.
- The Task (workflow process) is core resource related to Patient, Practioner, and PlanDefinition. A PlanDefinition/Practitioner/Patient can run multiple Task, but for each Task only can relate to one specific PlanDefinition/Practitioner/Patient.
- All the results of the workflow process are stored in Observation, and none of Patient resource is refer to them, all of them are refer to a Composition resource which is managed by a specific Task (workflow process).
Now, with this nice diagram, we can start the implementaion for this scienario.
Setup environment
- Same to Tutorial 02
Introduction
Import library
At the beginning we need to import libraries fhirpy and os.
Also, we re-use the customise function pprint from Tutorial-02. We'll use it to display some Observation resource data structures.
import os
from fhirpy import AsyncFHIRClient
from pathlib import Path
import pydicom
from datetime import datetime
import uuidimport os
from fhirpy import AsyncFHIRClient
from pathlib import Path
import pydicom
from datetime import datetime
import uuidCreate an instance of connection
To load data from FHIR server we should instaniate FHIRClient class from fhirpy AsyncFHIRClient method.
Let's pass url and authorization arguments from environment.
client = AsyncFHIRClient(
url='http://localhost:8080/fhir/',
authorization='Bearer TOKEN',
)client = AsyncFHIRClient(
url='http://localhost:8080/fhir/',
authorization='Bearer TOKEN',
)Now, we are able to operate with FHIR resources using client.
The Sequence Diagram for runing a workflow
Based on the scenario information, we can draw a sequence diagram for researcher Jiali when she run a workflow for a specific patient (Linman).

Implemention
Register a research role
Based on the research information above, we need to store the research data into Practitioner resource. The key idea here is we need to store the identifier for the researcher, this is a way for us to aviod the duplication resource instances and enable search funtion more easily.
- Check if there is a duplicate Practitioner resource
async def is_resource_exist(client, identifier, resource):
workflows = await search_resource(client, identifier=identifier, resource=resource)
if len(workflows) > 0:
print(f"the {resource} already exist! identifier: {identifier}")
return True
return False
result = await is_resource_exist(client, identifier, "Practitioner")
if result:
returnasync def is_resource_exist(client, identifier, resource):
workflows = await search_resource(client, identifier=identifier, resource=resource)
if len(workflows) > 0:
print(f"the {resource} already exist! identifier: {identifier}")
return True
return False
result = await is_resource_exist(client, identifier, "Practitioner")
if result:
return- Create a Practitioner resource for researcher
new_practitioner = create_resource(client, 'Practitioner', identifier)
new_practitioner['name'] = [
{
'given': ['Jiali'],
'family': 'Thompson',
'use': 'official',
}
]
# format year-month-day
new_practitioner['brithDate'] = '1975-09-20'
await new_practitioner.save()new_practitioner = create_resource(client, 'Practitioner', identifier)
new_practitioner['name'] = [
{
'given': ['Jiali'],
'family': 'Thompson',
'use': 'official',
}
]
# format year-month-day
new_practitioner['brithDate'] = '1975-09-20'
await new_practitioner.save()- As for we can eaily create a resource with
Identifier, we can create a common functioncreate_resource:
def create_resource(client, resource_type, resource_identifier):
resource = client.resource(resource_type)
resource['identifier'] = [
{
"use": "official",
"system": "http://sparc.sds.dataset",
"value": resource_identifier
}
]
return resourcedef create_resource(client, resource_type, resource_identifier):
resource = client.resource(resource_type)
resource['identifier'] = [
{
"use": "official",
"system": "http://sparc.sds.dataset",
"value": resource_identifier
}
]
return resourceLoad dataset
In this part, we don't to load a real dataset, what we can do is using a mock data. For example, we have a SDS dataset, and under the dataset primary folder we can two patients' subjects - which includes the patient's basic information (name, brithdate, contact), some EHR data (age, body temperature), or Dicom Images. So let's create our mock data:
[
{
"givenname": "Aniyah",
"familyname": '',
"identifier": "sparc-patient-yyds-001",
"brithDate": "1994-04-11",
"Observation": [
{
"identifier": "sparc-patient-yyds-001-observation-001",
"loinc-code": "8310-5",
"value": 96.8,
"unit-code": "degF"
},
{
"identifier": "sparc-patient-yyds-001-observation-002",
"loinc-code": "30525-0",
"value": 30,
"unit-code": "years"
}
]
},
{
"givenname": "Linman",
"familyname": "Zhang",
"identifier": "sparc-patient-yyds-002",
"brithDate": "1993-04-10",
"Observation": [
{
"identifier": "sparc-patient-yyds-002-observation-001",
"loinc-code": "8310-5",
"value": 93.8,
"unit-code": "degF"
},
{
"identifier": "sparc-patient-yyds-002-observation-002",
"loinc-code": "30525-0",
"value": 31,
"unit-code": "years"
}
]
}
][
{
"givenname": "Aniyah",
"familyname": '',
"identifier": "sparc-patient-yyds-001",
"brithDate": "1994-04-11",
"Observation": [
{
"identifier": "sparc-patient-yyds-001-observation-001",
"loinc-code": "8310-5",
"value": 96.8,
"unit-code": "degF"
},
{
"identifier": "sparc-patient-yyds-001-observation-002",
"loinc-code": "30525-0",
"value": 30,
"unit-code": "years"
}
]
},
{
"givenname": "Linman",
"familyname": "Zhang",
"identifier": "sparc-patient-yyds-002",
"brithDate": "1993-04-10",
"Observation": [
{
"identifier": "sparc-patient-yyds-002-observation-001",
"loinc-code": "8310-5",
"value": 93.8,
"unit-code": "degF"
},
{
"identifier": "sparc-patient-yyds-002-observation-002",
"loinc-code": "30525-0",
"value": 31,
"unit-code": "years"
}
]
}
]Now with these mock data, we can very easily create the Patient and Observation resources.
Create all Patients.
- Create
Patientresource
pynew_patient = create_resource(client, 'Patient', info['identifier']) new_patient['name'] = [ { 'given': [info['givenname']], 'family': info['familyname'], 'use': 'official', } ]new_patient = create_resource(client, 'Patient', info['identifier']) new_patient['name'] = [ { 'given': [info['givenname']], 'family': info['familyname'], 'use': 'official', } ]- Update reference to
PractitionerviaPatientgeneralPractitioner field
pyresearcher = await search_single_resource(client, identifier="sparc-practitioner-yyds-001", resource="Practitioner") new_patient["generalPractitioner"] = [ { "reference": researcher.to_reference().reference, "display": "Dr Adam Careful" } ] await new_patient.save()researcher = await search_single_resource(client, identifier="sparc-practitioner-yyds-001", resource="Practitioner") new_patient["generalPractitioner"] = [ { "reference": researcher.to_reference().reference, "display": "Dr Adam Careful" } ] await new_patient.save()- Create
Create
Observationresources for storingprimary measurements- See code in
T-03 observation-resourcefor how to create a Observation resource - Add
Patientreference to Observation viaObservationsubject field
pypatients = await search_resource(client, patient_identifier, 'Patient') patient = patients[0] new_observation['subject'] = patient.to_reference() await new_observation.save()patients = await search_resource(client, patient_identifier, 'Patient') patient = patients[0] new_observation['subject'] = patient.to_reference() await new_observation.save()- See code in
Upload workflow
When the researchers upload the workflow, we need to provide a template for them. In the template we need ask user to provide:
titletypedateversiondescriptionauthoraction: the output for each step, which FHIR resources needs to be generated.
{
"title": "breast computational workflow one",
"type": "workflow-definition",
"date": "2024-04-10",
"description": "A computational workflow defines all actions of calculate the closest distance from tumour to nipple in breast research. It also will record the tumour size.",
"purpose": """
# Purpose
## Record size
- Record tumour size
## Calculate closest distance.
- Closest distance between tumour and nipple
- Closest distance between tumour and skin
- Closest distance between tumour and ribcage
""",
"author": [
{
"name": "Jiali"
}
],
"action": [
{
"id": "breast_workflow_action_01",
"title": "calculate closest distance from tumour to nipple",
"output": [{
"type": "Observation",
"profile": "http://hl7.org/fhir/us/mcode/StructureDefinition/mcode-tumor-size"
}]
},
{
"id": "breast_workflow_action_02",
"title": "calculate tumour size",
"output": [{
"type": "Observation",
"profile": "http://hl7.org/fhir/us/mcode/StructureDefinition/mcode-tumor-size"
}]
}
]
}{
"title": "breast computational workflow one",
"type": "workflow-definition",
"date": "2024-04-10",
"description": "A computational workflow defines all actions of calculate the closest distance from tumour to nipple in breast research. It also will record the tumour size.",
"purpose": """
# Purpose
## Record size
- Record tumour size
## Calculate closest distance.
- Closest distance between tumour and nipple
- Closest distance between tumour and skin
- Closest distance between tumour and ribcage
""",
"author": [
{
"name": "Jiali"
}
],
"action": [
{
"id": "breast_workflow_action_01",
"title": "calculate closest distance from tumour to nipple",
"output": [{
"type": "Observation",
"profile": "http://hl7.org/fhir/us/mcode/StructureDefinition/mcode-tumor-size"
}]
},
{
"id": "breast_workflow_action_02",
"title": "calculate tumour size",
"output": [{
"type": "Observation",
"profile": "http://hl7.org/fhir/us/mcode/StructureDefinition/mcode-tumor-size"
}]
}
]
}With these information we can create a PlanDefinition resource to store the workflow description.
result = await is_resource_exist(client, identifier, "PlanDefinition")
if result:
return
workflow = client.resource('PlanDefinition')
workflow['identifier'] = [
{
"use": "official",
"system": "http://sparc.sds.dataset",
"value": identifier
}
]
workflow["title"] = description['title']
workflow["type"] = description['type']
workflow["date"] = description['date']
workflow["description"] = description['description']
workflow["purpose"] = description['purpose']
workflow["author"] = description['author']
workflow["action"] = description['action']
workflow['version'] = version
await workflow.save()result = await is_resource_exist(client, identifier, "PlanDefinition")
if result:
return
workflow = client.resource('PlanDefinition')
workflow['identifier'] = [
{
"use": "official",
"system": "http://sparc.sds.dataset",
"value": identifier
}
]
workflow["title"] = description['title']
workflow["type"] = description['type']
workflow["date"] = description['date']
workflow["description"] = description['description']
workflow["purpose"] = description['purpose']
workflow["author"] = description['author']
workflow["action"] = description['action']
workflow['version'] = version
await workflow.save()Execute workflow
When researcher execute the workflow, it needs to triggle fhir server to generate a Task for storing workflow process information.
Store workflow process
- As for store workflow process for
Taskresource, we also need to consider which fields should be used for reference - Key fields for references:
focus- workflow: PlanDefinitionowner- researcher: Practitionerrequester- patient: Patient
workflows = await search_resource(client, identifier=workflow_id, resource='PlanDefinition')
practitioners = await search_resource(client, identifier=practitioner_id, resource='Practitioner')
patients = await search_resource(client, identifier=patient_id, resource='Patient')
workflow = workflows[0]
practitioner = practitioners[0]
patient = patients[0]
result = await is_resource_exist(client, workflow_process_id, "Task")
if result:
return
new_task = create_resource(client, 'Task', workflow_process_id)
new_task['focus'] = workflow.to_reference()
new_task['owner'] = practitioner.to_reference()
new_task['requester'] = patient.to_reference()
new_task['lastModified'] = '2024-04-12T00:00:00Z'
await new_task.save()workflows = await search_resource(client, identifier=workflow_id, resource='PlanDefinition')
practitioners = await search_resource(client, identifier=practitioner_id, resource='Practitioner')
patients = await search_resource(client, identifier=patient_id, resource='Patient')
workflow = workflows[0]
practitioner = practitioners[0]
patient = patients[0]
result = await is_resource_exist(client, workflow_process_id, "Task")
if result:
return
new_task = create_resource(client, 'Task', workflow_process_id)
new_task['focus'] = workflow.to_reference()
new_task['owner'] = practitioner.to_reference()
new_task['requester'] = patient.to_reference()
new_task['lastModified'] = '2024-04-12T00:00:00Z'
await new_task.save()Store workflow process results
As for each workflow process, we also need to store their results into Observation resources. Here, let's assume there are two type of results we need to save:
- Closest distance
- Closest distance between tumour to nipple.
- Closest distance between tumour to skin.
- Closest distance between tumour to ribcage.
- Tumour size
new_observation = create_resource(client, 'Observation', result['identifier'])
new_observation['component'] = []
for component in result['component']:
component_temp = {
"code": {
"coding": [
{
"system": "http://ABI-breast-workflow",
"code": component['loinc-code'],
"display": component['display']
},
]
},
"valueQuantity": {
"value": component['value'],
"system": "http://unitsofmeasure.org",
"code": component['unit-code']
}
}
new_observation['component'].append(component_temp)new_observation = create_resource(client, 'Observation', result['identifier'])
new_observation['component'] = []
for component in result['component']:
component_temp = {
"code": {
"coding": [
{
"system": "http://ABI-breast-workflow",
"code": component['loinc-code'],
"display": component['display']
},
]
},
"valueQuantity": {
"value": component['value'],
"system": "http://unitsofmeasure.org",
"code": component['unit-code']
}
}
new_observation['component'].append(component_temp)Create a Composition
After we saved the results into FHIR Obseravtion resources, We also need to create a Composition resource to manage the results of the specific Task (workflow). Which means all result Observation resources should ref to this Composition resource. And this Composition resource should refer to Task and Patient.
- Key references in
Compositionresourcesubject: workflow process: Taskauthor: patient: Patient
workflow_processes = await search_resource(client, identifier=workflow_process_id, resource='Task')
patients = await search_resource(client, identifier=patient_id, resource='Patient')
workflow_process = workflow_processes[0]
patient = patients[0]
composition = create_resource(client, "Composition", composition_identifier)
composition['subject'] = {
"reference": workflow_process.to_reference().reference,
"display": f"Task: {workflow_process_id}"
},
composition['author'] = [
{
"reference": patient.to_reference(),
"display": "Patient"
}
]
composition['title'] = f"Task: {workflow_process_id} results"
composition['date'] = "2024-04-15T09:10:14Z"
composition['section'] = []
for result in result_info:
result_observations = await search_resource(client, result['identifier'], 'Observation')
result_observation = result_observations[0]
section = {
"title": result['title'],
"entry": [{
"reference": result_observation.to_reference().reference
}]
}
composition['section'].append(section)
await composition.save()workflow_processes = await search_resource(client, identifier=workflow_process_id, resource='Task')
patients = await search_resource(client, identifier=patient_id, resource='Patient')
workflow_process = workflow_processes[0]
patient = patients[0]
composition = create_resource(client, "Composition", composition_identifier)
composition['subject'] = {
"reference": workflow_process.to_reference().reference,
"display": f"Task: {workflow_process_id}"
},
composition['author'] = [
{
"reference": patient.to_reference(),
"display": "Patient"
}
]
composition['title'] = f"Task: {workflow_process_id} results"
composition['date'] = "2024-04-15T09:10:14Z"
composition['section'] = []
for result in result_info:
result_observations = await search_resource(client, result['identifier'], 'Observation')
result_observation = result_observations[0]
section = {
"title": result['title'],
"entry": [{
"reference": result_observation.to_reference().reference
}]
}
composition['section'].append(section)
await composition.save()Search entire workflow
print("*************************************** Search Results ************************************************")
# TODO 4.1 Find all workflow process of the workflow: sparc-workflow-yyds-001
workflow = await search_single_resource(client, identifier="sparc-workflow-yyds-001", resource="PlanDefinition")
tasks = await client.resources('Task').search(focus=workflow.to_reference()).fetch_all()
print("TODO 4.1: Search all workflow process of the workflow: sparc-workflow-yyds-001")
print(tasks)
print()
print("***************************************************************************************")
# TODO 4.2 find composition of the workflow process: sparc-workflow-yyds-001-process-002
workflow_process = await search_single_resource(client, identifier="sparc-workflow-yyds-001-process-002",
resource="Task")
compositions = await client.resources('Composition').search(subject=workflow_process.to_reference()).fetch_all()
print(f"TODO 4.2: All compositions of workflow process {workflow_process.to_reference()}")
print(compositions)
print()
print("***************************************************************************************")
# TODO 4.3 Find Researcher:sparc-practitioner-yyds-001 all workflow process of workflow: sparc-workflow-yyds-001
workflow = await search_single_resource(client, identifier="sparc-workflow-yyds-001", resource="PlanDefinition")
researcher = await search_single_resource(client, identifier="sparc-practitioner-yyds-001", resource='Practitioner')
workflow_processes = await client.resources('Task').search(focus=workflow.to_reference(),
owner=researcher.to_reference()).fetch_all()
print(
f"TODO 4.3: All workflow process of researcher sparc-practitioner-yyds-001 related to workflow: sparc-workflow-yyds-001")
print(workflow_processes)
print()
print("***************************************************************************************")
# TODO 4.4 Get the patient: sparc-patient-yyds-002 all workflow process of Researcher:sparc-practitioner-yyds-001 and workflow: sparc-workflow-yyds-001
workflow = await search_single_resource(client, identifier="sparc-workflow-yyds-001", resource="PlanDefinition")
researcher = await search_single_resource(client, identifier="sparc-practitioner-yyds-001", resource='Practitioner')
patient = await search_single_resource(client, identifier="sparc-patient-yyds-002", resource="Patient")
workflow_processes = await client.resources('Task').search(focus=workflow.to_reference(),
owner=researcher.to_reference(),
requester=patient.to_reference()).fetch_all()
print(
f"TODO 4.4: Get the patient: sparc-patient-yyds-002 all workflow process of Researcher:sparc-practitioner-yyds-001 and workflow: sparc-workflow-yyds-001")
print(workflow_processes)
print()
print("***************************************************************************************")
# TODO 4.5 Get Patient Linman: sparc-patient-yyds-002 all result observation
linman = await search_single_resource(client, identifier="sparc-patient-yyds-002", resource="Patient")
workflow_processes = await client.resources('Task').search(requester=linman.to_reference()).fetch_all()
for process in workflow_processes:
composition = await client.resources("Composition").search(subject=process.to_reference()).first()
for section in composition['section']:
for ob in section['entry']:
print("TODO 4.5: the observation result of linman:")
b = await ob.to_resource()
print(b['identifier'])
print()
print("***************************************************************************************")print("*************************************** Search Results ************************************************")
# TODO 4.1 Find all workflow process of the workflow: sparc-workflow-yyds-001
workflow = await search_single_resource(client, identifier="sparc-workflow-yyds-001", resource="PlanDefinition")
tasks = await client.resources('Task').search(focus=workflow.to_reference()).fetch_all()
print("TODO 4.1: Search all workflow process of the workflow: sparc-workflow-yyds-001")
print(tasks)
print()
print("***************************************************************************************")
# TODO 4.2 find composition of the workflow process: sparc-workflow-yyds-001-process-002
workflow_process = await search_single_resource(client, identifier="sparc-workflow-yyds-001-process-002",
resource="Task")
compositions = await client.resources('Composition').search(subject=workflow_process.to_reference()).fetch_all()
print(f"TODO 4.2: All compositions of workflow process {workflow_process.to_reference()}")
print(compositions)
print()
print("***************************************************************************************")
# TODO 4.3 Find Researcher:sparc-practitioner-yyds-001 all workflow process of workflow: sparc-workflow-yyds-001
workflow = await search_single_resource(client, identifier="sparc-workflow-yyds-001", resource="PlanDefinition")
researcher = await search_single_resource(client, identifier="sparc-practitioner-yyds-001", resource='Practitioner')
workflow_processes = await client.resources('Task').search(focus=workflow.to_reference(),
owner=researcher.to_reference()).fetch_all()
print(
f"TODO 4.3: All workflow process of researcher sparc-practitioner-yyds-001 related to workflow: sparc-workflow-yyds-001")
print(workflow_processes)
print()
print("***************************************************************************************")
# TODO 4.4 Get the patient: sparc-patient-yyds-002 all workflow process of Researcher:sparc-practitioner-yyds-001 and workflow: sparc-workflow-yyds-001
workflow = await search_single_resource(client, identifier="sparc-workflow-yyds-001", resource="PlanDefinition")
researcher = await search_single_resource(client, identifier="sparc-practitioner-yyds-001", resource='Practitioner')
patient = await search_single_resource(client, identifier="sparc-patient-yyds-002", resource="Patient")
workflow_processes = await client.resources('Task').search(focus=workflow.to_reference(),
owner=researcher.to_reference(),
requester=patient.to_reference()).fetch_all()
print(
f"TODO 4.4: Get the patient: sparc-patient-yyds-002 all workflow process of Researcher:sparc-practitioner-yyds-001 and workflow: sparc-workflow-yyds-001")
print(workflow_processes)
print()
print("***************************************************************************************")
# TODO 4.5 Get Patient Linman: sparc-patient-yyds-002 all result observation
linman = await search_single_resource(client, identifier="sparc-patient-yyds-002", resource="Patient")
workflow_processes = await client.resources('Task').search(requester=linman.to_reference()).fetch_all()
for process in workflow_processes:
composition = await client.resources("Composition").search(subject=process.to_reference()).first()
for section in composition['section']:
for ob in section['entry']:
print("TODO 4.5: the observation result of linman:")
b = await ob.to_resource()
print(b['identifier'])
print()
print("***************************************************************************************")Summary
In this tutorial the following topics were covered:
Patient,Practitioner,PlanDefinition,Task,CompositionandObservationresources.- How to implement based on the reference relationship structure.
- How to search resources under a specific condition.
- Find all workflow processes for a given workflow
- Find the composition for each workflow processes
- Find all workflows processes that a specific researcher has started for a given workflow
- Find all workflows processes that belong to a specific patient that a specific researcher has started for a given workflow
- Find all workflow result observations for a specific patient
- Find all primary measurements for a given patient